About This Site#
This site provides various popular and powerful generative AI services.This is the public API documentation of this site, where you can view the API documentation for development and debugging purposes.OpenAI's Audio, Chat, Completions, Embeddings, Images, and Moderations interfaces are all supported. The paths and parameters are consistent with OpenAI's. Here we only list some platform-customized and public API documentation. For specific OpenAI-compatible interfaces, please refer to the official documentation: https://platform.openai.com/docs/api-referenceIn actual use, you only need to select one of the API endpoints below as the base URL to replace https://api.openai.com, or append the path in the following documentation.US Main Site Direct Connection Stable, Unavailable in Some Regions: https://api.ohmygpt.com
Cloudflare CDN Stable, Global Acceleration: https://cfcus02.opapi.win
Cloudflare Worker Stable, Global Acceleration: https://cfwus02.opapi.win
High-quality Route Reverse Proxy 1 High-quality Route, Availability Not Guaranteed: https://aigptx.top
High-quality Route Reverse Proxy 2 High-quality Route, Availability Not Guaranteed: https://cn2us02.opapi.win
However, when using streaming call API interfaces, you will not be affected by this timeout limit of Cloudflare.vision#
Although the built-in chat on the website does not provide Vision functionality, you can call it through the open API provided by this site in conjunction with third-party open-source/closed-source software.LobeChat#
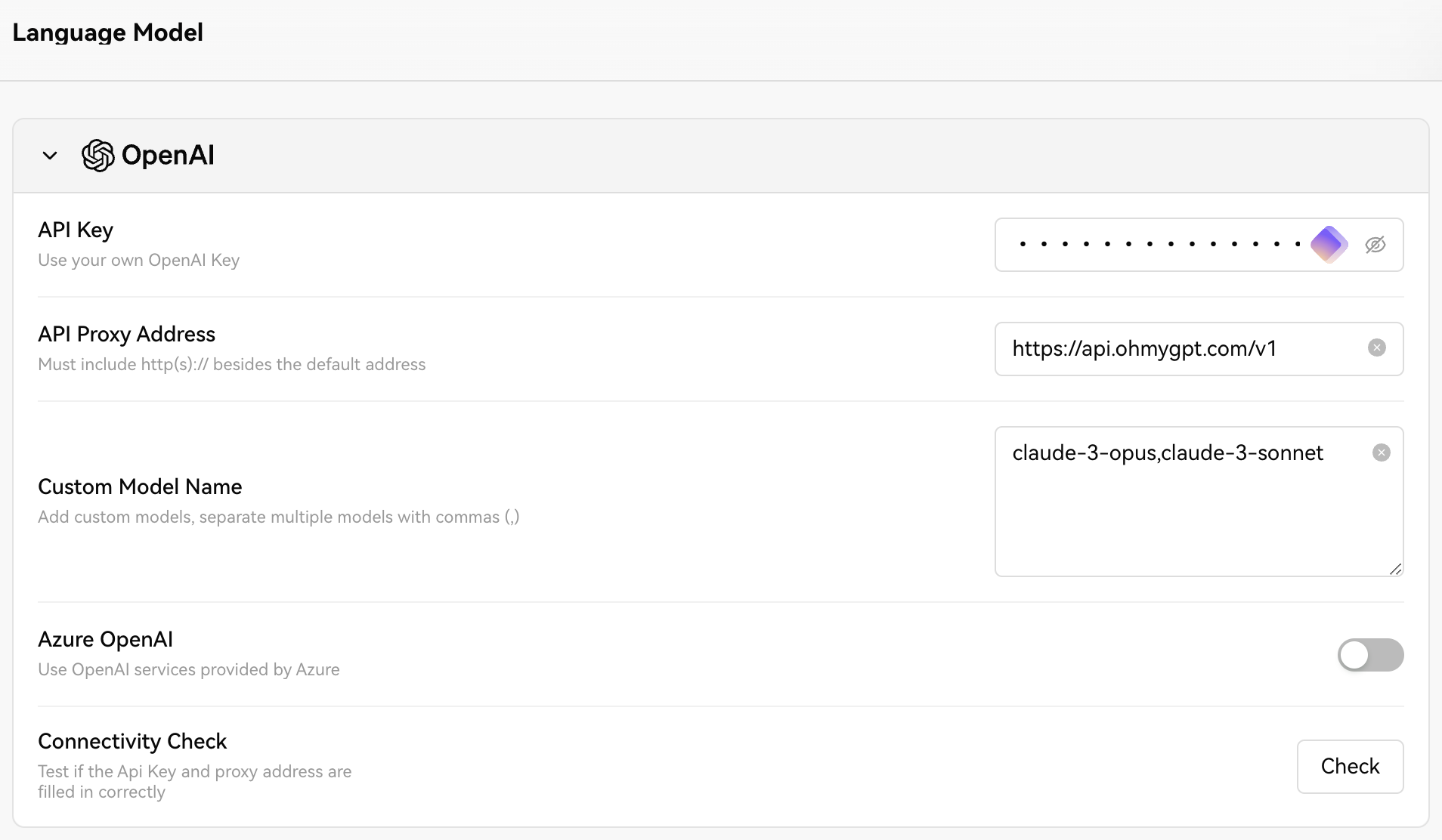
Click the link to enter the website, then click on the settings in the lower right corner.Configure it as shown in the image:API Key: Fill in the API Key generated in the "Settings" of this site.
API Proxy Address: Fill in https://api.ohmygpt.com/v1
Custom Model Name: You can fill in models from the Claude series, such as claude-3-opus,claude-3-sonnet
BotGem(AMA)#
Can I directly use my own OpenAI key on this site?#
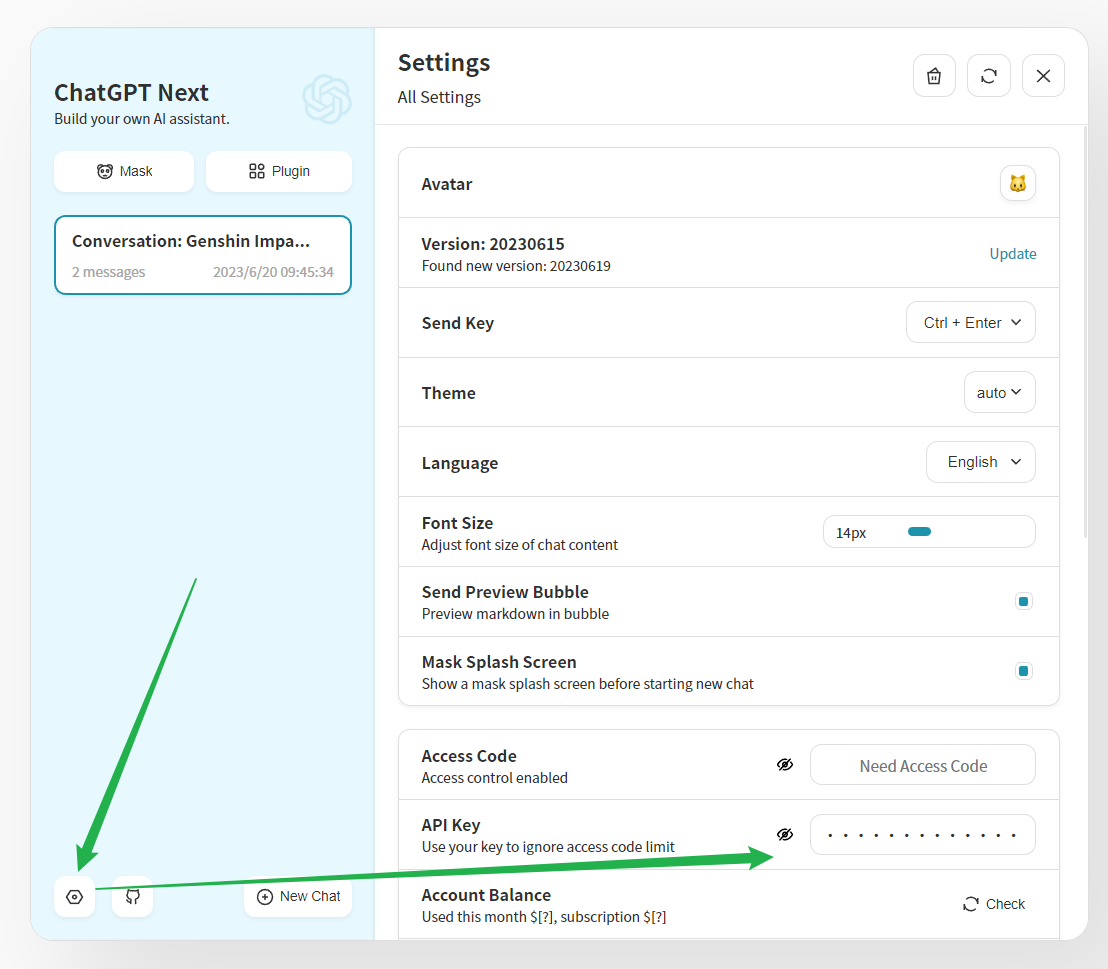
No, uploading your own key is not supported on this site.How do I use this site's services in chatGPT-next-web?#
How do I use this site's services in GPT Academic Optimization?#
This instance is hosted by this site. You can directly fill in the API Key generated in the settings of this site to use it:Before using, make two modifications to config.py:1.
Modify the API_KEY on line 11 of config.py to your own key from this site.
2.
Modify the API_URL_REDIRECT value on line 38 of config.py to {"https://api.openai.com/v1/chat/completions": "https://aigptx.top/v1/chat/completions"}
How do I use this site's Claude2 service in GPT Academic Optimization?#
First, please make sure you need to use the Claude2 service. Second, using this site's Claude2 in GPT Academic Optimization requires more configuration and is more complicated.1.
Modify the API_KEY on line 11 of config.py to your own key from this site.
2.
Modify the API_URL_REDIRECT value on line 38 of config.py to {"https://api.openai.com/v1/chat/completions": "https://aigptx.top/v1/chat/completions"}
3.
Add the model "claude-2-web" to AVAIL_LLM_MODELS on line 73 of config.py.
4.
On line 622 of toolbox.py, modify the code to:Please pay attention to the indentation. 5.
Add a key-value pair to the model_info variable in request_llm/bridge_all.py: About Memberships and GPT4#
As shown below, this site offers three plans: Free, VIP, and Premium.
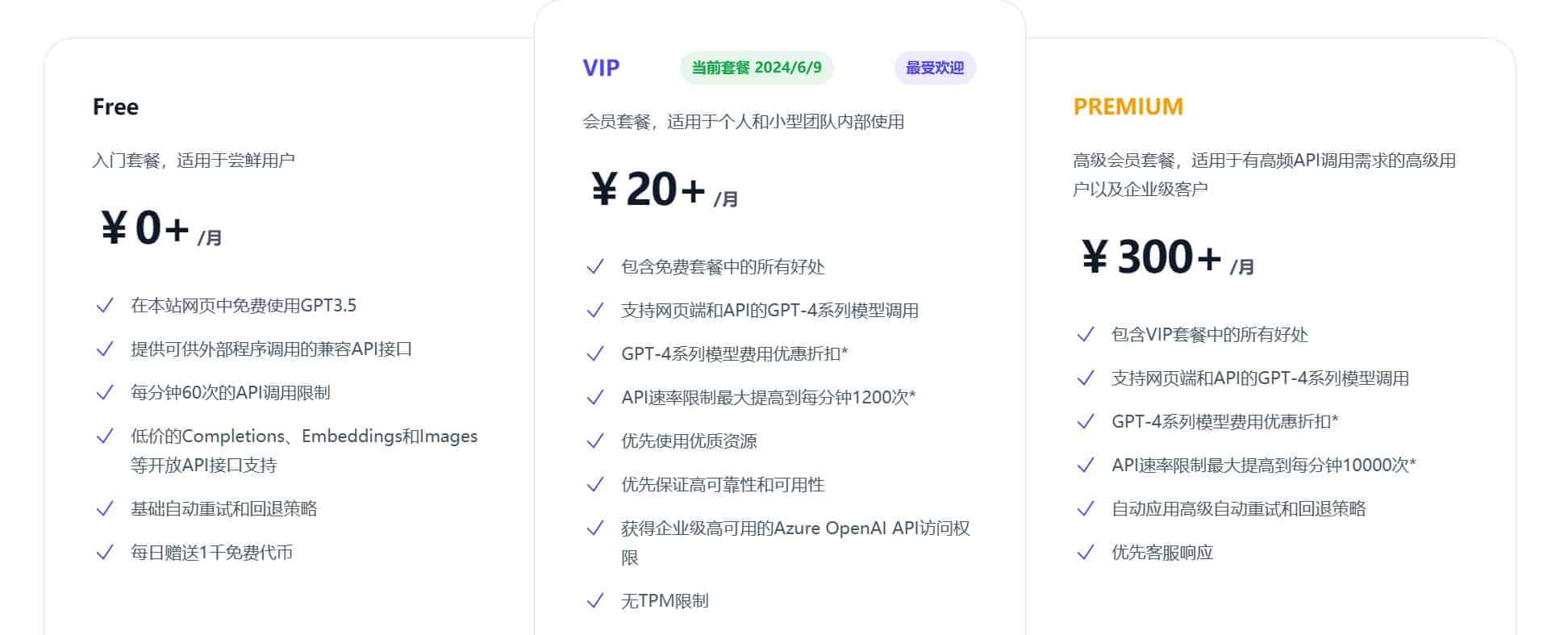 VIP and Premium can unlock API services for all models (including GPT4).
VIP and Premium can unlock API services for all models (including GPT4).How do I get access to GPT4?#
You need to upgrade your plan to VIP to get access to GPT4. This is the lowest-cost way for you on this site and the way we most recommend you use.Upgrading to VIP is simple. You only need to top up 20 RMB on this site to get one month of VIP qualification; topping up 40 RMB can get you six months of VIP qualification. As long as you top up the specified amount, you can get VIP qualification without paying for the VIP qualification itself.Is the VIP plan a monthly subscription plan?#
No, after topping up, you will get tokens to offset the consumption of each service use. The VIP qualification is a gift after you top up, and your token balance will not be deducted because you obtained the VIP qualification.I topped up 20 RMB and my VIP qualification expired. How long can I get VIP access if I top up another 20 RMB?#
The image below can help you better understand our billing mechanism.
 In this situation, your multiple payments met the VIP conditions. Starting from the time of your first payment, you will get the corresponding duration of VIP access time.The main reason you encounter this situation is DNS pollution and SNI blocking from GFW.
In this situation, your multiple payments met the VIP conditions. Starting from the time of your first payment, you will get the corresponding duration of VIP access time.The main reason you encounter this situation is DNS pollution and SNI blocking from GFW.About Cost Consumption#
How to calculate the cost consumption?#
Except for midjourney, the actual cost deducted by the system is: the cost calculated by the official AI service multiplied by the current rate.For example, if you have successfully requested a GPT4 request worth 1 RMB according to the official pricing, it will be multiplied by the corresponding service rate at that time (for example, 0.5), then the actual cost deducted will be 1*0.5=0.5 RMB.What does each column in the billing table represent?#
promptTokens: The context length used by the model for understanding
completionTokens: The text length generated by the model
RURT: Request upload time (in milliseconds ms)
TPS: Request time (in seconds)
Free: Whether this request consumes free quota
What are promptTokens and completionTokens?#
For language models, each vocabulary is converted from human language to a vector that the model can understand in the form of a "vocabulary table", and each mapping corresponds to a token. In other words, token is the smallest unit for language models to understand text.At the same time, the interaction of language models has two steps: receiving text and replying with a response. It can be simply understood that you need to ask the model a question before the model will give you a reply. Among them, the number of tokens in the question asked is promptTokens, and the length of the text replied is completionTokens.In addition, the pricing for promptTokens and completionTokens varies for different language models, so they need to be distinguished.Why are there a lot of promptTokens when using the web version?#
Models do not have memory capabilities similar to humans. If you need to relate this question to previous questions, you need to send the previous question content and the model's reply content together to the model. This is the main reason for the large promptTokens value.If you need to save costs, reducing the context amount in advanced settings can effectively reduce the size of promptTokens for each conversation.Why is there a system role in addition to the user and model roles in the web version?#
The system role corresponds to the system role in OpenAI's API, and it is used to determine the role the model plays and the function it performs in this session.If you need to save costs by reducing context, the system is the last context to be removed. For example:If the context length is 0, the message sent with the request will only contain your question.
If the context length is 1, in addition to your question, the message sent with the request will include the system.
If the context length is greater than 1, in addition to your question and the system, the message sent with the request will include the most recent conversation to this conversation.
About API#
You can integrate various capabilities into your applications through the open API of this site.I'm a beginner. Can you provide a code example for calling the service?#
When calling the OpenAI service, you can choose to use the official OpenAI Python library or use a more general request library + API for integration, either of which works.The following sample code uses this site's service to send a request and obtain the result in a non-streaming way, and then print it on the console.
First, you need to prepare your key.Modified at 2024-09-04 14:11:00